リスキルキャリア
リスキルキャリア 

ChatGPTの登場以降、多くの企業が生成AIの業務導入を進めています。しかし「回答が正しいか判断できない」「社内情報を反映できない」といった壁に直面するケースは少なくありません。こうした課題を解決する技術として、いま急速に存在感を増しているのがRAG(検索拡張生成)です。本記事では、RAGの基礎知識から実装の仕組み、国内企業の導入事例、さらにはキャリアへの活かし方まで、実務に役立つ情報を体系的に解説します。技術者はもちろん、AI活用を推進するビジネスパーソンにとっても、次の一手を見つけるヒントになるはずです。
この記事の監修者

リスキルキャリア編集部
リスキルキャリアは、生成AI時代にリスキリング・副業・転職で収入UPを目指す方に向けた情報を発信するWebメディアです。編集部では、スキルを活かしたキャリアアップの方法やおすすめのスクールなどをお届けしています。
RAGとは生成AIの回答精度を高める検索拡張生成の技術
RAGは、生成AIが抱える情報の鮮度や正確性の課題を克服するために生まれた技術です。ここでは、RAGの基本概念から注目される理由、他の手法との違いまでを整理します。
RAG(Retrieval-Augmented Generation)の意味と基本概念
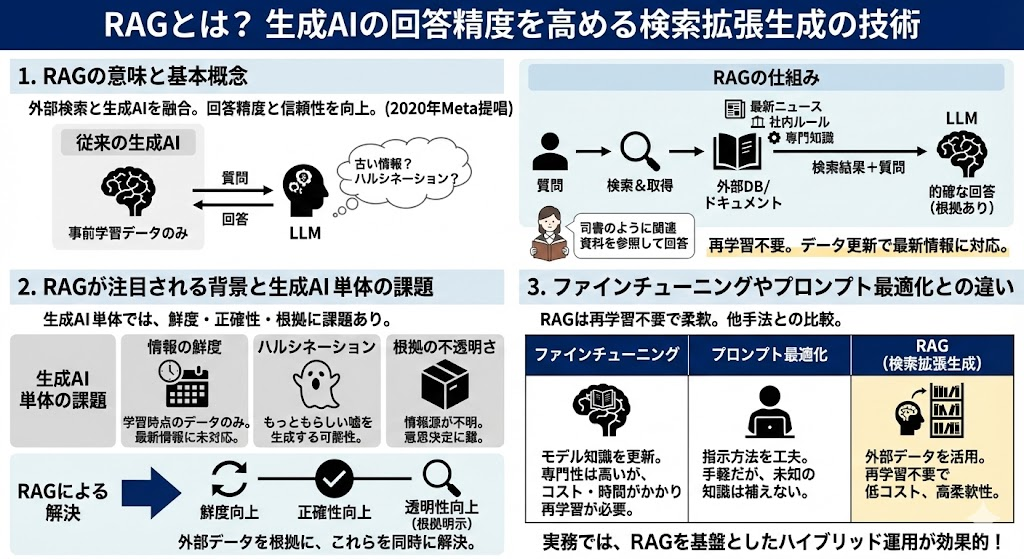
RAG(Retrieval-Augmented Generation)は、日本語で「検索拡張生成」と訳される技術で、生成AIに外部情報の検索機能を組み合わせることで、回答の精度と信頼性を高める仕組みです。2020年にMeta(旧Facebook)の研究者Patrick Lewisらが発表した論文「Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks」(NeurIPS 2020)で提唱されました。
従来の生成AIは、事前に学習したデータの範囲内でしか回答できません。一方RAGでは、ユーザーから質問を受けるたびに外部のデータベースやドキュメントを検索し、取得した情報をもとにLLM(大規模言語モデル)が回答を生成します。たとえるなら、図書館の司書が利用者の質問に対して関連する資料を探し出し、その内容を参考にしながら的確な回答を組み立てるイメージです。モデル自体を再学習させる必要がなく、検索対象のデータを更新するだけで最新情報を反映できる点が大きな特徴です。
RAGが注目される背景と生成AI単体の課題
ChatGPTをはじめとする生成AIの急速な普及に伴い、ビジネスの現場でもAI活用が進んでいます。しかし、生成AI単体での運用にはいくつかの課題が顕在化しています。
まず、情報の鮮度の問題です。LLMは学習時点までのデータしか持たないため、最新のニュースや法改正、社内ルールの変更などには対応できません。次に、ハルシネーション(誤情報の生成)の問題があります。LLMは学習データに基づいてもっともらしい文章を生成しますが、事実に基づかない情報を自信を持って出力してしまうことがあります。さらに、回答の根拠が不透明であるという課題もあります。どの情報源を参照して回答を導いたのかがわからないため、ビジネス上の意思決定に使いづらい場面が生じます。
RAGはこれらの課題に対して、外部データベースからの検索結果を回答の根拠として活用することで、情報の鮮度・正確性・透明性を同時に向上させます。企業が生成AIを安心して業務に導入するための基盤技術として、注目が高まっています。
▼参考記事
・ハルシネーションとは?原因・事例・5つの対策を初心者にもわかりやすく解説
ファインチューニングやプロンプト最適化との違い
生成AIの回答品質を向上させるアプローチは、RAGだけではありません。代表的な手法であるファインチューニングとプロンプト最適化との違いを理解することで、RAGの位置づけがより明確になります。
ファインチューニングは、LLMに追加データを学習させてモデルの知識そのものを更新する方法です。専門分野の知識を深く組み込めるメリットがある一方、大量の学習データと計算リソースが必要で、情報更新のたびに再学習が発生するためコストと時間がかかります。プロンプト最適化は、質問文の構成や指示の出し方を工夫することでAIの出力を改善する手法です。手軽に取り組める反面、効果は設計者のスキルに左右され、モデルが持たない知識を補うことはできません。
これに対しRAGは、モデルの再学習を行わずに外部データを検索して回答に反映できるため、最新情報への対応コストが低く、データの追加・差し替えも柔軟です。実務では、RAGを基盤としつつ、必要に応じてファインチューニングやプロンプト最適化を組み合わせるハイブリッドな運用が効果的とされています。
RAGの仕組みを「検索」と「生成」の流れで理解する
RAGは大きく「データの準備」「関連情報の検索」「回答の生成」という3つのステップで動作します。それぞれの工程で何が行われているのかを順に見ていきましょう。
知識ベースの準備とデータのベクトル化
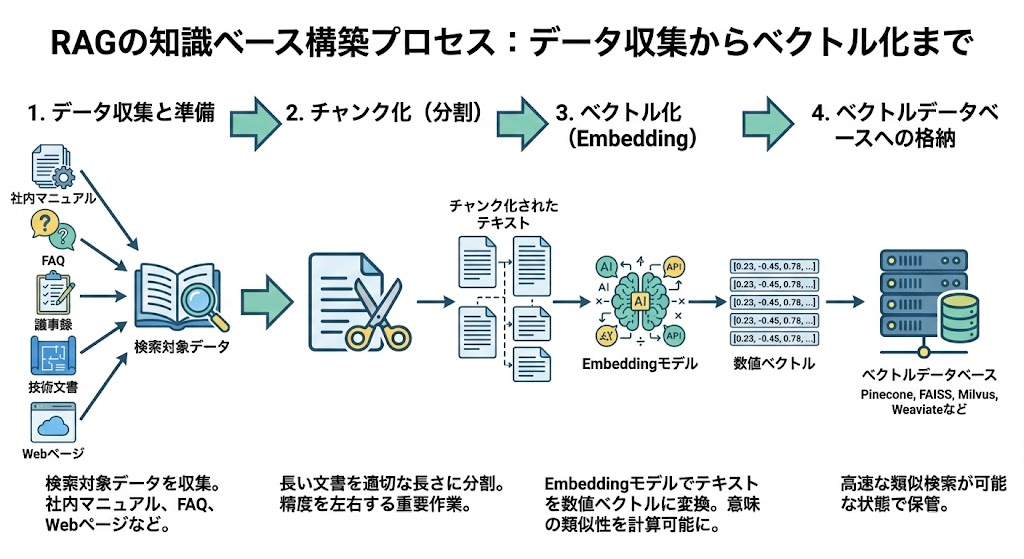
RAGを機能させるには、まず回答の根拠となる知識ベースを構築する必要があります。社内マニュアル、FAQ、議事録、技術文書、Webページなど、検索対象としたいデータを収集するところから始まります。
収集したデータは、そのままではAIが効率的に検索できないため、「チャンク化」と「ベクトル化(Embedding)」という処理を行います。チャンク化とは、長い文書を意味のまとまりごとに適切な長さに分割する作業です。分割の粒度はRAGの検索精度を大きく左右し、大きすぎると情報がぼやけ、小さすぎると文脈が失われてしまいます。
分割されたテキストは、Embeddingモデル(OpenAIのEmbeddings APIやBERTなど)によって数百〜数千次元の数値ベクトルに変換されます。この変換により、テキストの意味的な類似性を数学的に計算できるようになります。変換後のベクトルデータは、Pinecone・FAISS・Milvus・Weaviateなどのベクトルデータベースに格納され、高速な類似検索が可能な状態で保管されます。
ユーザーの質問に対する関連情報の検索プロセス
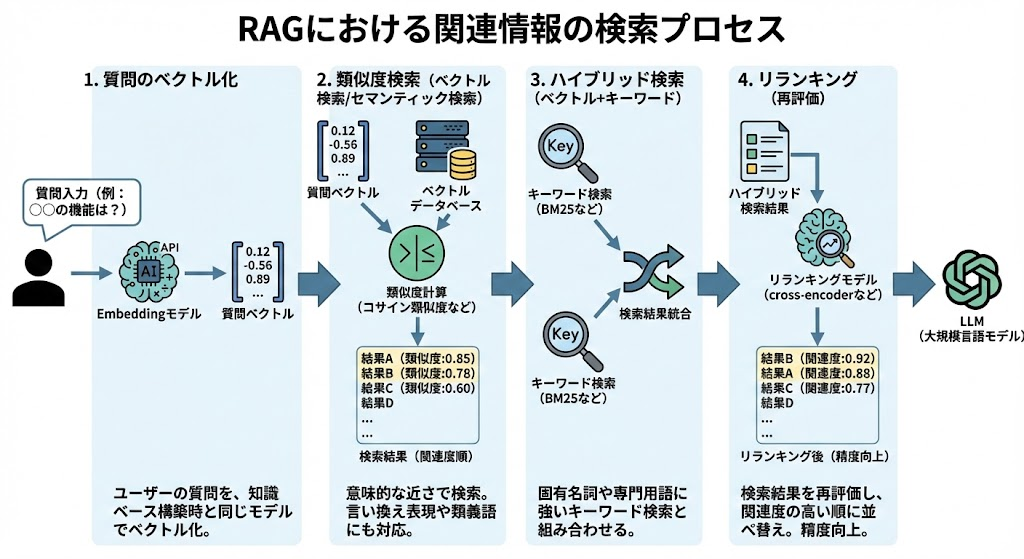
ユーザーが質問を入力すると、RAGシステムはその質問文を知識ベースの構築時と同じEmbeddingモデルでベクトル化し、ベクトルデータベース内のデータとの類似度を計算して関連性の高い情報を抽出します。このプロセスが「ベクトル検索(セマンティック検索)」です。単語の完全一致ではなく意味的な近さで検索するため、言い換え表現や類義語にも対応できる強みがあります。
ただし、ベクトル検索だけでは固有名詞や専門用語の正確なマッチングが弱い場合があります。そこで実務では、キーワードの一致度を重視するBM25などの「キーワード検索(疎検索)」と組み合わせた「ハイブリッド検索」が主流となっています。さらに精度を高めるために、検索結果を再評価して関連度の高い順に並べ替える「リランキング」処理を行うケースもあります。cross-encoderモデルを用いた再ランキングは特に精度が高く、重要な情報を確実に上位に配置できます。
検索結果をもとにLLMが回答を生成する流れ
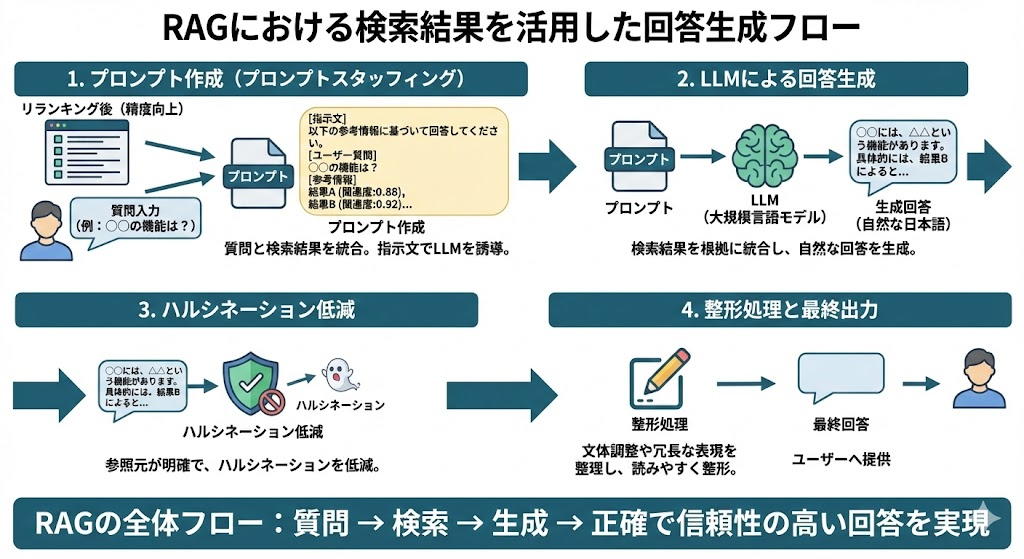
検索で取得された関連情報は、ユーザーの質問文と組み合わせて「プロンプト」としてLLMに入力されます。このプロンプトには、「以下の参考情報に基づいて回答してください」といった指示文が含まれ、LLMが検索結果を根拠として活用するよう誘導します。この手法は「プロンプトスタッフィング」とも呼ばれます。
LLMは、入力されたプロンプトの内容を理解し、検索結果の情報を統合しながら自然な日本語で回答を生成します。事前学習した知識だけに頼る場合と比べて、参照元が明確な根拠付きの回答となるため、ハルシネーションのリスクが大幅に低減されます。生成後には、文体の調整や冗長な表現の整理といった整形処理が行われ、読みやすい最終出力として提供されます。このように、RAGでは「質問→検索→生成」という一連の流れが、正確で信頼性の高い回答を実現する基盤となっています。
RAGを導入するメリットと知っておくべき限界
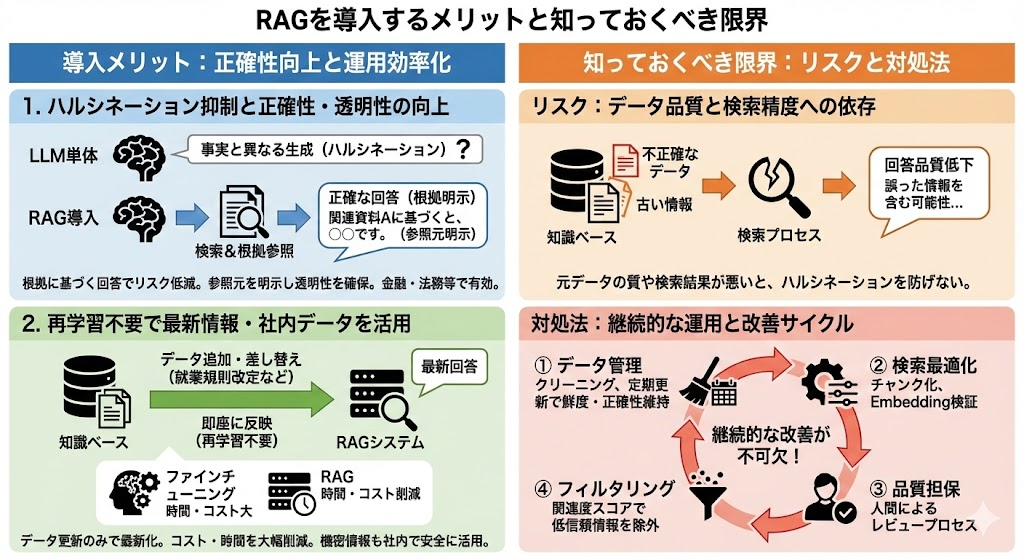
RAGは生成AIの実用性を飛躍的に高める技術ですが、万能ではありません。ここでは導入によって得られる具体的なメリットと、運用上知っておくべきリスクや対処法を解説します。
ハルシネーションを抑え正確な回答を実現できる
RAG導入の最大のメリットは、生成AIの回答に「根拠」が伴うようになることです。LLM単体では、学習データに含まれない情報について事実と異なる内容を生成してしまうハルシネーションのリスクがありますが、RAGでは検索で取得した実際のドキュメントを参照して回答を組み立てるため、このリスクを大幅に低減できます。
さらに、回答の生成時にどのドキュメントを参照したかを明示できるため、利用者が回答の正確性を自分で検証できる透明性が確保されます。この特性は、金融・法務・医療などの正確性が特に求められる領域で導入が進んでいる理由の一つです。社内の意思決定プロセスにおいても、根拠が示された回答であれば、関係者間の合意形成がスムーズになります。
最新情報や社内データを再学習なしで活用できる
RAGは、検索対象となる知識ベースのデータを更新するだけで、LLMの回答に最新情報を反映できます。ファインチューニングのようにモデル自体を再学習させる必要がないため、情報更新にかかる時間とコストを大幅に削減できる点が実務上の大きな利点です。
たとえば、社内の就業規則が改定された場合、従来の方法ではモデルを再学習させるか、プロンプトに手動で情報を追加する必要がありました。RAGであれば、改定後のドキュメントを知識ベースに追加・差し替えするだけで、AIチャットボットが最新の規則に基づいた回答を返せるようになります。同様に、製品マニュアルの更新や新しい社内通達の反映も迅速に対応可能です。自社固有の非公開データをAIに活用させる際にも、データを外部に出さず社内環境で完結できるため、機密情報を扱いやすい利点があります。
データ品質や検索精度に依存するリスクへの対処法
RAGの回答品質は、知識ベースに格納されたデータの質と検索精度に大きく依存します。不正確なデータや古い情報が混在していれば、RAGを導入してもハルシネーションを完全には防げません。また、検索プロセスで適切な情報を取得できなければ、回答の質は低下します。
これらのリスクに対処するためには、運用面での継続的な取り組みが不可欠です。具体的には、データのクリーニングと定期的な更新によって知識ベースの鮮度と正確性を維持すること、チャンク化の粒度やEmbeddingモデルの選定を検証して検索精度を最適化すること、そして人間によるレビュープロセスを組み込んで回答品質を担保することが重要です。また、検索結果の関連度スコアに閾値を設け、信頼性の低い情報をフィルタリングする仕組みを取り入れることも効果的です。RAGは「導入して終わり」ではなく、継続的な改善が求められる技術であることを認識しておく必要があります。
RAGの活用事例に学ぶ業務改善のヒント
RAGはすでに多くの日本企業で実用化され、業務効率化や顧客対応の高度化に貢献しています。ここでは、公開されている代表的な導入事例をもとに、活用のヒントを紹介します。
社内ナレッジ検索とFAQチャットボットでの活用
LINEヤフー株式会社は、RAG技術を活用した独自の社内情報検索ツール「SeekAI」を全従業員に本格導入しました(出典:LINEヤフー株式会社 2024年7月11日付プレスリリース)。SeekAIは、社内のワークスペースツールやデータを参照元として、従業員が入力した質問に対して部門やプロジェクトごとに最適化された回答を返すツールです。
テスト導入の段階で、広告事業のカスタマーサポート業務では約98%の正答率を達成しました。エンジニアがコーディング業務を行う際の技術スタック検索・選定にかかる時間も削減されています。同社はSeekAIの活用により、年間70〜80万時間の業務削減を目指しています。この事例は、RAGを社内ナレッジ検索の基盤に据えることで、部門横断的な業務効率化を実現できることを示しています。
カスタマーサポートの自動化と品質向上
東京地下鉄株式会社(東京メトロ)は、Allganize Japan株式会社と協力し、2024年11月にRAGを活用した生成AIチャットボットの本格サービスを開始しました(出典:東京メトロ 2024年11月28日付ニュースリリース)。鉄道会社としてお客様向けチャットボットとお客様センター業務の双方に生成AIを本格導入するのは、国内初の取り組みです。
従来のFAQ型チャットボットでは対応できなかった多様な質問に対して、RAG技術により公式Webサイトの情報から適切な回答を自動生成し、対応範囲を大幅に拡大しました。年間約25万件の電話と約10万件のメールに対応するお客様センターでは、メール問い合わせの内容把握・情報検索・回答案生成を自動化し、オペレーターの業務負荷を軽減しています。
専門分野でのドキュメント分析と意思決定支援
出光興産株式会社は、RAGを中核とした生成AIシステムを導入し、社内外のデータを横断的に活用する環境を構築しました(出典:ウルシステムズ株式会社 2025年5月15日付 PR TIMESプレスリリース)。先進マテリアル部門では、競合製品の分析レポート作成と技術サポートの2つの業務にRAGを適用しています。
競合分析では、インターネットや特許データベースから競合製品の情報を自動収集・分析し、開発予定の新素材が市場で優位性を持つかを評価するレポートを生成します。技術サポートでは、製品の不具合に関する問い合わせを受けた際に、顧客管理システムやクラウドストレージから類似事例を検索し、迅速な原因特定と対応を支援しています。この事例は、RAGが単なる情報検索にとどまらず、専門的な判断を伴う意思決定支援にも有効であることを示しています。
RAGの今後の進化とAIエージェントとの融合
RAGの技術は急速に進化しており、従来の「検索して生成する」という枠組みを超えた次世代のアーキテクチャが登場しています。ここでは、最新の技術動向とAIエージェントとの融合について解説します。
Advanced RAGやGraph RAGなど次世代アーキテクチャの動向
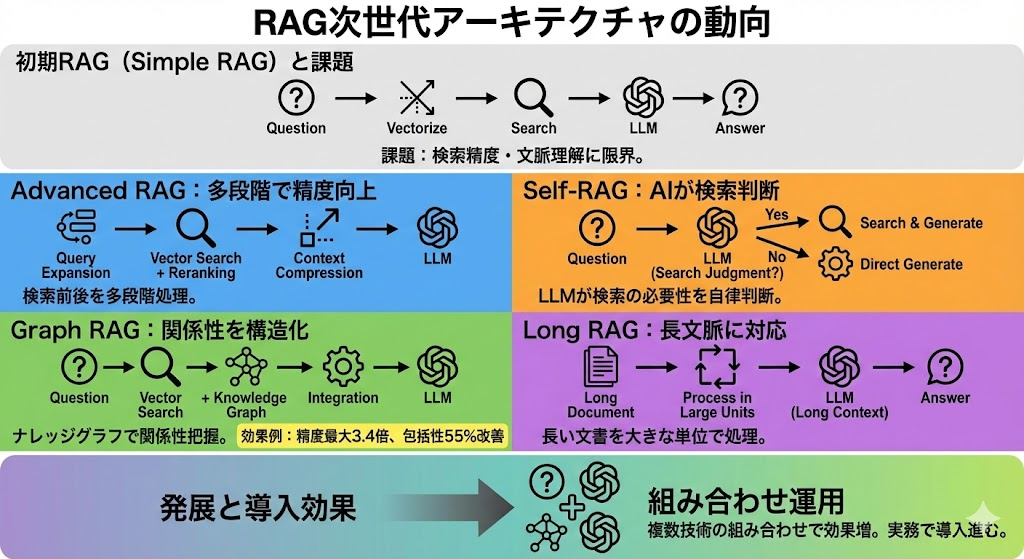
初期のRAGは「質問をベクトル化して類似文書を検索し、LLMに渡す」というシンプルな構成でした。しかし、実務で運用する中で検索精度や文脈理解の限界が明らかになり、これらを克服するための発展型アーキテクチャが次々と提案されています。
「Advanced RAG」は、検索前のクエリ拡張、検索後のリランキング、コンテキスト圧縮などの処理を多段階に組み合わせて検索精度を高めるアプローチの総称です。また「Graph RAG」は、ベクトル検索にナレッジグラフ(知識グラフ)を組み合わせることで、エンティティ間の関係性を構造的に捉えた検索を可能にします。ある研究では、Graph RAGの導入により従来手法と比べて最大3.4倍の精度向上や、回答の包括性が55%改善した事例も報告されています。
さらに、LLM自身が「今回は検索が必要かどうか」を判断する「Self-RAG」や、長い文書を大きな単位のまま処理することで文脈の断絶を防ぐ「Long RAG」など、課題に特化した手法も発展しています。これらの技術は単独で使われるだけでなく、組み合わせて運用されるケースが増えており、実務での導入効果が高まっています。
AIエージェントがRAGを自律的に活用する時代の到来
2025年のAI業界では「AIエージェント」が最大の注目テーマとなりましたが、その基盤技術としてRAGの重要性はむしろ高まっています。AIエージェントとは、与えられた目標に対して計画を立て、ツールを使い分けながら自律的にタスクを遂行するAIシステムです。このエージェントが正確な判断を下すためには、適切なコンテキスト(文脈情報)をリアルタイムで取得する必要があり、そこでRAGが不可欠な役割を果たします。
「Agentic RAG」と呼ばれるアプローチでは、AIエージェントが検索クエリの生成、検索結果の評価、追加検索の判断といったプロセスを自律的に実行します。従来の固定的な検索パイプラインとは異なり、状況に応じて検索戦略を動的に切り替えられるため、複雑なタスクへの対応力が飛躍的に向上します。RAGは単なる「検索拡張生成」の枠を超え、AIエージェントのあらゆる文脈組み立てを支える「Context Engine(コンテキストエンジン)」へと進化しつつあります。この流れは、RAGスキルを持つ人材の市場価値がさらに高まることを示唆しています。
RAGを仕事・キャリアに活かすための実践ガイド
RAGの知識は、エンジニアだけでなくビジネス職にとっても価値のあるスキルです。ここでは、職種や経験を問わずRAGをキャリアに活かすための具体的な考え方と学習ステップを紹介します。
非エンジニアでも押さえておきたいRAG活用の考え方
RAGの構築にはプログラミングスキルが必要ですが、RAGを「活用する」側であれば、技術的な実装スキルがなくても十分にキャリアに活かせます。重要なのは、RAGの仕組みと特性を理解し、自社の業務課題のどこにRAGが適用できるかを見極める視点を持つことです。
たとえば、営業部門であれば「過去の提案資料や商談履歴をRAGで検索可能にし、提案品質を均一化する」といった活用が考えられます。人事部門なら「就業規則や社内制度のFAQをRAGで自動回答化する」という発想が可能です。このような業務改善の企画力があれば、非エンジニアでもRAGプロジェクトの推進者として活躍できます。DifyやMicrosoft Copilot Studioなど、ノーコード・ローコードでRAGを構築できるツールも充実してきており、技術的なハードルは年々下がっています。
RAGの構築に必要な技術スタックと学習ステップ
エンジニアとしてRAGシステムを構築するには、複数の技術領域を横断するスキルが求められます。主要な技術スタックとして押さえておきたい要素は以下の通りです。
プログラミング言語とフレームワーク
・Python:RAG開発の主要言語であり必須
・LangChain / LlamaIndex:RAGパイプライン構築の代表的フレームワーク
・Haystack:情報検索とLLM統合に強みを持つ選択肢
データ処理と検索基盤
・Embeddingモデル:OpenAI Embeddings API、BERT系モデルなど
・ベクトルDB:Pinecone、FAISS、Milvus、Weaviateなど
・BM25 / ハイブリッド検索:キーワード検索との組み合わせ
LLMとAPI連携
・OpenAI API / Claude API / Azure OpenAI:主要LLMサービスとの連携
・プロンプトエンジニアリング:検索結果を効果的にLLMに渡す設計スキル
学習ステップとしては、まずPythonの基礎を固めた上で、LangChainなどのフレームワークを使って小規模なRAGアプリを実装するところから始めるのが効果的です。公式ドキュメントやQiita・Zennなどの技術記事、そしてAWSやGoogle Cloudが提供するRAGのチュートリアルが実践的な学習リソースとして活用できます。
RAGスキルが求められる職種と今後のキャリアパス
RAGに関連するスキルへの需要は急速に拡大しています。求人サイトで「RAG エンジニア」と検索すると、大手企業からスタートアップまで多数の求人がヒットする状況です。RAGスキルが特に求められている職種としては、AIエンジニア、MLOpsエンジニア、データサイエンティスト、そしてAIコンサルタントが挙げられます。
実際の求人では、本田技研工業のナレッジマネジメントAI基盤エンジニア(RAG・生成AI活用)や、三井住友カードのAIエンジニア(LangChain、RAG、ベクトルDB)、NTT東日本のRAGシステム開発エンジニアなど、業種を問わず募集が広がっています(出典:Indeed 2025年求人情報より)。フリーランスとしてRAGの構築案件に携わる場合、月額80万〜100万円前後の案件も見られます。
キャリアパスとしては、RAGエンジニアから出発して、AIアーキテクトやテックリードへとステップアップする道のほか、特定の業界(金融・医療・法務など)のドメイン知識と組み合わせて専門特化する方向性も有望です。AIエージェントの発展に伴いRAGの重要性はさらに増しており、この領域のスキルを今から積み上げることは、中長期的なキャリア形成において大きなアドバンテージとなるでしょう。
まとめ:RAGを理解して生成AI活用の次のステップへ進もう
RAG(検索拡張生成)は、生成AIに外部データの検索機能を組み合わせることで、回答の正確性・情報の鮮度・透明性を同時に向上させる技術です。2020年のMeta論文で提唱されて以降、急速に進化を遂げ、LINEヤフーや東京メトロ、出光興産といった日本企業でも実用化が進んでいます。ハルシネーションの抑制や再学習不要でのデータ活用といったメリットがある一方、データ品質への依存や検索精度の最適化といった運用上の課題もあり、継続的な改善が欠かせません。今後はAdvanced RAGやGraph RAG、AIエージェントとの融合によって、RAGの活用範囲はさらに広がると見込まれます。エンジニアにとっては技術スタックの習得が直接的なキャリアアップにつながり、非エンジニアにとっても業務改善の企画力として価値を発揮するスキルです。まずはRAGの基本を理解し、自身の業務や学習に活かす第一歩を踏み出してみてください。