
「ChatGPTの回答、本当に合っているのだろうか」——生成AIを使うたびに、こんな不安を感じたことはないでしょうか。生成AIが事実と異なる情報をもっともらしく出力する「ハルシネーション」は、業務での活用が広がるほど見過ごせないリスクになっています。実際に、AIの誤情報を鵜呑みにしたことで法的トラブルや企業価値の毀損につながった事例も報告されています。
本記事では、ハルシネーションの正体から発生の仕組み、実際に起きた事件、そして今日から使える具体的な防止策までを一つひとつ丁寧に解説します。さらに、この知識をAI時代のキャリアにどう活かせるかについても触れています。生成AIを「なんとなく便利」で終わらせず、リスクを理解したうえで確かな武器にしたい方は、ぜひ最後までお読みください。
この記事の監修者

リスキルAIキャリア編集部
リスキルAIキャリアは、AI時代の学び直し・キャリア形成・副業・転職に役立つ情報を発信するWebメディアです。編集部では、生成AIスキルの身につけ方、AI関連スクール・講座の選び方、キャリアアップにつながる学習方法などを、実務目線でわかりやすくお届けしています。
ハルシネーションとは生成AIが「もっともらしい嘘」を出力する現象

ここでは、ハルシネーションの基本的な意味や語源、種類の違い、そして注目される背景について解説します。
ハルシネーションの意味と語源
ハルシネーション(Hallucination)とは、生成AIが事実とは異なる情報を、あたかも正しいかのようにもっともらしく出力してしまう現象のことです。英語の「Hallucination」は本来「幻覚」や「幻影」を意味する医学・心理学用語ですが、AIが実在しない情報をまるで幻を見ているかのように生成する様子から、この名称が転用されるようになりました。
たとえば、存在しない研究論文をタイトル・著者名・掲載ジャーナルまで含めて回答したり、架空の歴史的事実を詳細に語ったりするケースが典型例です。特に厄介なのは、出力された内容が一見すると論理的で説得力があるように見えてしまう点です。正確な情報の中に自然な形で誤情報が紛れ込むため、利用者が誤りに気づかず信じてしまうリスクがあります。
2026年時点の技術では、ハルシネーションの発生を完全に防ぐことは困難とされています。OpenAIが2025年に発表した報告でも、最新モデルにおいてもこの問題は根本的に解消されていないことが示されました。生成AIを活用する際は「間違える可能性がある」という前提を持つことが大切です。
内在的ハルシネーションと外在的ハルシネーションの違い
ハルシネーションは、その性質によって「内在的ハルシネーション(Intrinsic Hallucination)」と「外在的ハルシネーション(Extrinsic Hallucination)」の2種類に分類されます。両者の違いを表で整理すると以下のとおりです。
| 種類 | 定義 | 具体例 |
|---|---|---|
| 内在的ハルシネーション(Intrinsic) | 学習済みデータと矛盾する情報を生成する | 記事の要約で元にない内容を追加する、数値や固有名詞を誤って出力する |
| 外在的ハルシネーション(Extrinsic) | 学習データに存在しない情報を創作する | 存在しない論文を引用する、架空の人物や出来事を詳細に語る |
内在的ハルシネーションは、学習データの中に正しい情報があるにもかかわらず、それと食い違う回答を生成してしまう点が特徴です。一方、外在的ハルシネーションは、そもそも根拠となるデータが存在しないにもかかわらず、モデルが確率的に「それらしい」情報を作り出してしまいます。
どちらのタイプも、利用者にとっては「正しい情報」と見分けがつきにくいという共通の危険性を持っています。
なぜ今ハルシネーションが注目されているのか
ハルシネーションという現象自体はAI研究の分野では以前から知られていましたが、社会的に大きく注目されるようになったのは2022年末以降のことです。ChatGPTの公開をきっかけに生成AIの利用者が爆発的に増加し、一般のビジネスパーソンや個人がAIの回答を日常的に活用する場面が急増しました。その結果、ハルシネーションによる誤情報が実際のトラブルにつながるケースが相次いで報告されるようになったのです。
企業における生成AIの業務活用も急速に進んでおり、社内問い合わせ対応や資料作成、市場分析など幅広い場面でAIの出力が利用されています。利用範囲が広がるほどハルシネーションが実務に及ぼすリスクも高まるため、AIの出力精度に対する関心はこれまで以上に高まっています。
加えて、各国でAI規制の議論が活発化していることも注目度を押し上げる要因となっています。EUのAI規制法(AI Act)をはじめ、AIの安全性や信頼性に関する法整備が進む中で、ハルシネーションへの対策は技術的課題にとどまらず、企業のガバナンスやコンプライアンスの観点からも重要なテーマとなっています。
ハルシネーションが起こる3つの原因
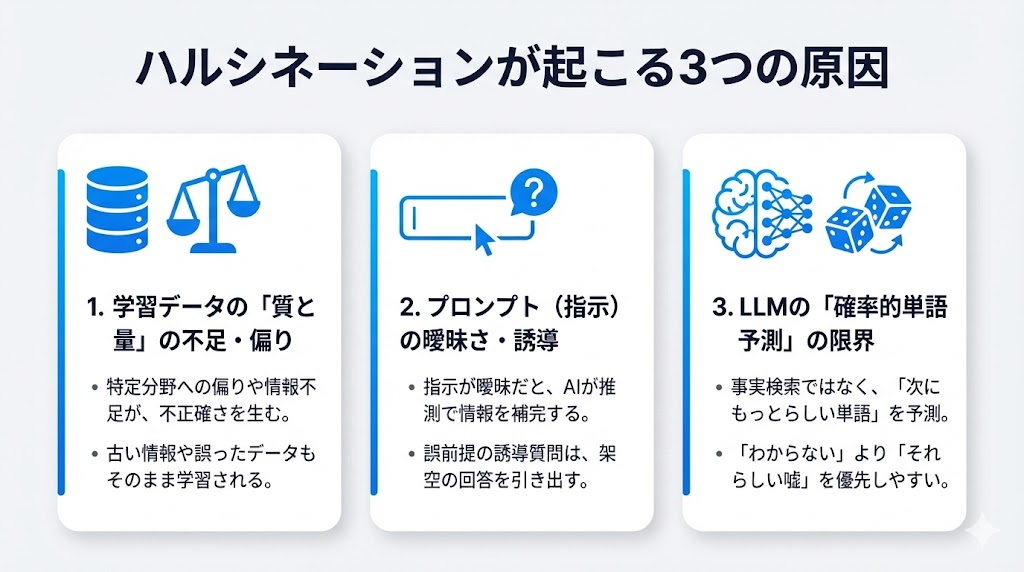
ハルシネーションが発生する背景には、主に3つの原因があります。それぞれのメカニズムを理解しましょう。
学習データの不足や偏りによる影響
生成AIの回答精度は、学習に使用されたデータの質と量に大きく左右されます。学習データが特定の分野やジャンルに偏っている場合、AIはその偏りを反映した不正確な回答を生成しやすくなります。たとえば、英語圏の情報が豊富でも日本語の専門情報が少なければ、日本固有の法律や制度について誤った内容を出力するリスクが高まります。
また、学習データの「鮮度」も重要な要素です。生成AIは学習が完了した時点までの情報しか保持していないため、学習後に起きた出来事や最新の研究成果については正確に回答できません。たとえば、最新の法改正や新しく発表された統計データについて質問すると、古い情報に基づいた回答や、知識の空白を補おうとして創作された誤情報が返される可能性があります。
さらに、学習データ自体に誤情報が含まれているケースも無視できません。インターネット上の大量のテキストを学習元としている場合、その中には不正確な記述や偏った意見も含まれています。AIにはデータの正誤を判断する能力がないため、誤った情報をそのまま学習し、回答に反映してしまうことがあるのです。
プロンプト(指示文)の曖昧さが招く誤情報
ユーザーが生成AIに与える指示、すなわちプロンプトの書き方もハルシネーションの発生に大きく影響します。プロンプトが曖昧であったり、主語や条件が不明確だったりすると、AIは不足している情報を推測で補完しようとするため、結果として事実と異なる内容を生成しやすくなります。
特に危険なのは、前提条件に誤りを含む誘導的なプロンプトです。たとえば「22世紀に活躍した日本の偉人について教えて」のように、事実としてあり得ない前提を含む質問を投げかけると、AIはその誤った前提に乗ったまま架空の人物像を作り出してしまいます。AIは質問の前提自体が正しいかどうかを検証する機能を持たないため、与えられた条件をそのまま受け入れて回答を生成するのです。
また、一度に複雑な条件を詰め込みすぎた指示も、ハルシネーションのリスクを高めます。複数の条件を同時に処理しようとする中で、AIが一部の条件を見落としたり誤解したりすることがあるためです。
LLMの「次の単語予測」という仕組み上の限界
ハルシネーションが起こる最も根本的な原因は、LLM(大規模言語モデル)の文章生成メカニズムそのものにあります。LLMは「次に続く可能性が最も高い単語(トークン)を確率的に予測する」という仕組みで文章を生成しています。つまり、事実を検索して正確な情報を返しているのではなく、学習データから得た統計的パターンに基づいて「それらしい文章」を組み立てているのです。
この仕組みは、自然で流暢な文章を作ることには非常に優れています。しかし、文章としての自然さと内容の正確性は必ずしも一致しません。AIは「事実かどうか」ではなく「文脈上もっともらしいかどうか」を基準に単語を選んでいるため、流暢だが事実に反する文章が生成されることがあります。
さらに、多くのLLMは何らかの回答を返すように最適化されているため、「わかりません」と答えるよりも「それらしい答え」を出力する傾向があります。知識が不足している分野の質問に対しても沈黙ではなく回答を試み、その結果として自信ありげに誤情報を語ってしまうのです。この「構造的な挙動」こそが、ハルシネーションを単なるバグとは異なる根深い課題にしています。
ハルシネーションによるトラブルの実例とビジネスへの影響
ハルシネーションは理論上のリスクではなく、すでに現実のトラブルを引き起こしています。代表的な事例と業務上のリスクを確認しましょう。
弁護士が架空の判例を裁判所に提出した事例
ハルシネーションが実社会で深刻な問題を引き起こした代表的な事例が、2023年にアメリカで起きた「Mata v. Avianca事件」です。ニューヨーク州の弁護士スティーブン・シュワルツ氏が、航空会社アビアンカを相手取った個人傷害訴訟の準備にChatGPTを使用しました。ChatGPTは過去の判例を求めるプロンプトに対し、実在しない6件の架空の判例を、もっともらしい事件名・引用番号・裁判所見解とともに生成しました。
シュワルツ氏はこれらの判例が実在するものと信じ、事実確認を行わないまま法廷文書に引用して裁判所に提出してしまいました。相手側弁護団の指摘により架空の判例であることが発覚し、裁判官から問い詰められた際にChatGPTの利用を認めました。最終的に、シュワルツ氏と同僚弁護士、所属する法律事務所に対して5,000ドルの制裁金が科されています(Mata v. Avianca, Inc., 678 F.Supp.3d 443, S.D.N.Y. 2023)。
この事件は世界的に報道され、生成AIの出力を無検証で業務に使用することの危険性を象徴する事例となりました。
Google Bardのデモで発覚した誤情報
企業のプロモーション段階でハルシネーションが露呈したケースもあります。2023年2月、GoogleはChatGPTに対抗する対話型AIサービス「Bard」の公式デモを公開しました。デモでは「ジェームズ・ウェッブ宇宙望遠鏡(JWST)の新発見について9歳の子どもに教えられることは何か」という質問に対し、Bardが「JWSTは太陽系外の惑星の写真を初めて撮影した」と回答しました。
しかし、太陽系外惑星を直接撮影したのは2004年にヨーロッパ南天天文台(ESO)のVLT望遠鏡が初めてであり、この回答は事実と異なるものでした。天文学者たちがSNS上で即座にこの誤りを指摘し、大きな話題となりました。この一件はGoogleの株価にも影響を与え、発覚直後の取引でAlphabet(Googleの親会社)の時価総額は約1,000億ドル(当時の為替レートで約13兆円)下落したと報じられています(出典:Forbes)。
この事例は、AI開発企業自身もハルシネーションを見落としうること、そしてその影響が企業価値に直結しうることを示しています。
業務シーン別に見るリスクの違い
ハルシネーションのリスクは、生成AIを使う業務の内容によって大きく異なります。リスクが特に高い場面を理解しておくことが、適切な運用の第一歩です。以下の表に、代表的な業務シーンごとのリスクレベルと想定される具体的なリスクを整理しました。
| 業務シーン | リスクの高さ | 想定される具体的リスク |
|---|---|---|
| 法務・コンプライアンス | 高 | 架空の判例・条文に基づく法的判断の誤り |
| マーケティング・広報 | 中〜高 | 誤った市場データや統計の外部公開による信頼失墜 |
| システム開発 | 中〜高 | 脆弱性を含むコードの混入によるセキュリティリスク |
| 顧客対応・カスタマーサポート | 中 | 誤った製品情報や対処法の案内によるクレーム発生 |
| アイデア出し・ブレインストーミング | 低 | 出力の正確性が厳密に問われないため影響は限定的 |
重要なのは、業務の性質に応じてAIへの依存度を調整し、リスクが高い場面ほど検証を徹底する姿勢です。前述のMata v. Avianca事件は法務領域のリスクが現実化した典型例であり、高リスク業務ではAIの出力をそのまま採用することは避けるべきです。
こんな質問は危険!ハルシネーションを誘発しやすいNGプロンプト集
ハルシネーションは、ユーザーの質問の仕方によって発生しやすさが大きく変わります。以下のようなプロンプトは特にリスクが高いため、業務で使用する際は注意が必要です。
ハルシネーションを誘発しやすい4つのNGパターン
・誤った前提を含む質問:まだ起きていない出来事や存在しない事実を前提にしている
・存在確認なしに詳細を求める質問:実在するか不明な論文や事例について直接詳細を要求している
・最新情報を断定的に求める質問:リアルタイムの株価や最新ニュースなど学習データの範囲外を求めている
・複数条件を一度に詰め込んだ質問:条件が多いほどAIが一部を推測で補完するリスクが高まる
NGプロンプトは、少し書き方を変えるだけでリスクを大幅に下げられます。以下の表で改善例を確認しましょう。
| NGプロンプト(危険) | 改善例(OKプロンプト) |
|---|---|
| 2050年にノーベル平和賞を受賞した日本人は誰ですか? | 過去にノーベル平和賞を受賞した日本人の一覧を教えてください |
| ○○という論文の要約を教えて | ○○というテーマの論文が実在するか確認してください |
| 現在の○○の株価はいくらですか? | ○○の直近の決算で報告された売上高を教えてください |
| 過去5年間のAI市場規模を年度別・業界別・競合比較付きで教えて | 2023年の日本国内AI市場規模について、出典付きで教えてください |
こうしたNGパターンを避け、具体的で検証可能な質問を心がけることが、ハルシネーションを未然に防ぐ第一歩です。
ハルシネーションを防ぐ5つの対策
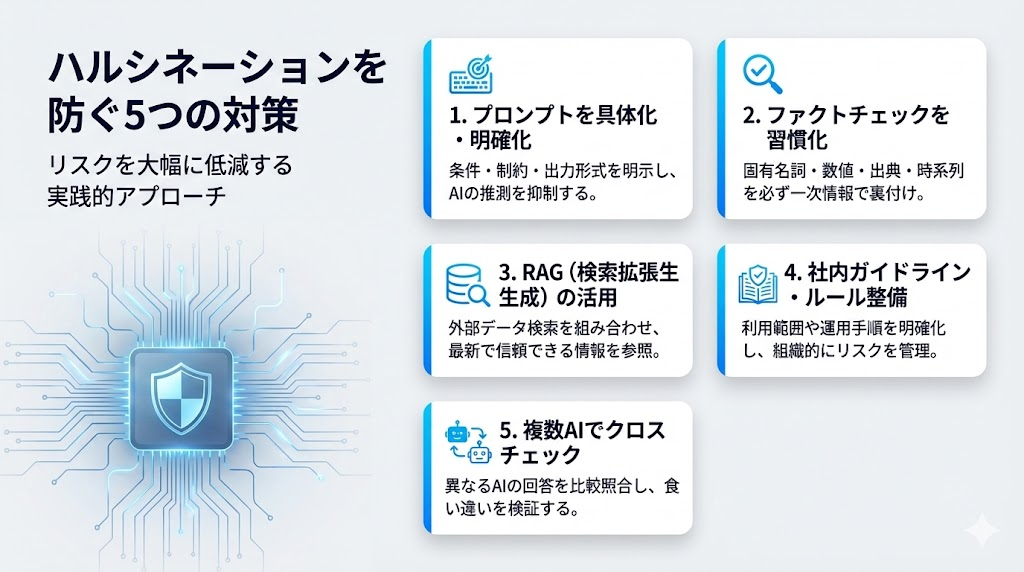
完全な防止は困難ですが、適切な対策を組み合わせることでリスクを大幅に低減できます。ここでは実践的な5つの方法を紹介します。
プロンプトの指示を具体的かつ明確にする
ハルシネーションを抑制するうえで最も手軽に取り組めるのが、プロンプト(指示文)の改善です。AIへの指示を明確にするだけで、誤情報の発生率を大きく下げることができます。効果的なプロンプト作成のポイントは以下の3つです。
プロンプト改善の3つのポイント
・条件を具体的に指定する:「最近のAI動向を教えて」ではなく「2024年1月以降に日本国内で施行された生成AI関連の法規制について教えて」のように主語・対象・期間を明示する
・回答に制約を設ける:「確実に事実である情報のみ回答してください」「不確かな場合は『確認が必要です』と明記してください」といった条件を付ける
・出力形式を指定する:「出典を併記してください」「根拠となるデータがあれば数値と一緒に示してください」と求め、後から検証しやすくする
これらのポイントを組み合わせることで、AIが推測で情報を補完することを抑え、出力の信頼性を高められます。
出力を見抜くためのファクトチェック実践法
プロンプトをどれだけ工夫しても、ハルシネーションの可能性はゼロにはなりません。そのため、AIの出力に対するファクトチェック(事実確認)を習慣化することが不可欠です。
個人レベルでは、AIの出力に対して最低限以下の3点をチェックする習慣をつけましょう。
ファクトチェックの3点チェックリスト
・固有名詞の確認:人名・組織名・書籍名・法律名などが実在するか検索エンジンで照合する
・数値・出典の検証:引用されたデータや統計の出典が実在し、数値が正確かを一次情報源で確認する
・時系列の整合性:出来事の順序や日付に矛盾がないか、事実関係の前後関係をチェックする
組織として取り組む場合は、チェック体制の仕組み化が重要です。担当者による一次チェックに加え、専門部署(法務・広報など)によるダブルチェック体制を構築すると、ハルシネーションが外部資料や公式文書に混入するリスクを大幅に減らせます。「誰が・どのタイミングで・どの方法で確認するか」をルールとして明文化しておくことが、チェック漏れを防ぐカギとなります。
RAG(検索拡張生成)を活用する
技術的な対策として注目されているのが、RAG(Retrieval-Augmented Generation:検索拡張生成)の活用です。RAGとは、生成AIの回答プロセスに外部データベースからの情報検索を組み合わせる技術で、AIが事前学習したデータだけに頼らず、最新かつ信頼性の高い情報源を参照しながら回答を生成できるようになります。
従来の生成AIは学習時点までの情報しか持たないため、知識のカットオフ以降の情報には対応できませんでした。RAGを導入すると、社内データベースや公式ドキュメント、最新のWebソースなどを検索したうえで回答を組み立てるため、情報の正確性と鮮度が向上します。
さらに、RAGを搭載したシステムの多くは、回答の根拠となった情報ソースを併せて表示する機能を持っています。万が一ハルシネーションが発生した場合でも、どの情報源に問題があったかを特定しやすく、原因の追跡と改善が容易になる点も大きなメリットです。企業がAIを本格的に業務導入する際は、RAG対応のシステムを検討する価値が十分にあります。
▼参考記事
・RAGとは?仕組みから活用事例・始め方まで初心者にもわかる完全ガイド
社内ガイドラインとマニュアルを整備する
技術的な対策と並んで重要なのが、組織としてのルール整備です。生成AIの利用に関するガイドラインやマニュアルを策定することで、従業員が安全にAIを活用できる環境を構築できます。
ガイドラインに盛り込むべき要素としては、まずAIの利用範囲の明確化があります。たとえば、「アイデア出しや情報収集の補助には使用可、外部向け公式文書の最終稿作成には使用不可」のように、業務の種類ごとにAI利用の可否を定めましょう。リスクの高い業務でのAI依存を制限することで、ハルシネーションに起因するトラブルを未然に防げます。
また、マニュアルには具体的な運用手順を記載します。効果的なプロンプトの書き方のテンプレート、ファクトチェックの実施手順、問題が発生した際のエスカレーションフローなどを明記しましょう。加えて、そもそもハルシネーションとは何か、どのような危険性があるかという基礎知識の周知も欠かせません。新入社員研修やeラーニングに組み込むことで、組織全体のAIリテラシー向上につなげられます。
複数のAIツールでクロスチェックする
一つのAIツールの出力だけを鵜呑みにせず、複数の生成AIやAI搭載検索エンジンを使ってクロスチェックすることも有効な対策です。それぞれのAIは異なる学習データやモデルアーキテクチャを基盤としているため、同じ質問に対しても異なる回答を返すことがあります。
たとえば、ChatGPTで得た情報をGeminiやClaudeなど別のAIに同じ質問を投げて照合したり、Perplexityのような情報源を明示するAI検索ツールで裏付けを取ったりする方法があります。複数のAIが一致した回答を返す場合は正確性が高い可能性がありますが、回答が食い違う場合はいずれかにハルシネーションが含まれている可能性があるため、一次情報源に立ち返って確認することが大切です。
クロスチェックは万能ではありませんが、単一のAIに依存するよりも誤情報を見落とすリスクを確実に低減できる実用的な手法です。
ハルシネーション対策のスキルをキャリアに活かすには
ハルシネーションへの理解と対策スキルは、AI時代のキャリアを切り拓く武器になります。具体的な活かし方を見ていきましょう。
AI時代に求められるリテラシーとは
生成AIが業務ツールとして定着しつつある今、すべてのビジネスパーソンに求められるのが「AIリテラシー」です。ここでいうAIリテラシーとは、プログラミングや機械学習の専門知識ではなく、AIの出力を適切に評価し、リスクを見極めたうえで業務に活用できる実践的な判断力を指します。
具体的には、AIが返す回答の正確性を疑い、必要に応じてファクトチェックを行えること、プロンプトを工夫して出力の質を高められること、そしてハルシネーションをはじめとするAI特有のリスクを理解したうえで利用範囲を判断できることが含まれます。
こうしたリテラシーは、エンジニア職に限らず、営業・マーケティング・法務・人事などあらゆる職種で価値を発揮します。「AIを使える人」ではなく「AIを正しく使いこなせる人」が、これからの組織で重宝される人材像です。
AIリスク管理の知識が活きる職種と転職先
ハルシネーション対策を含むAIリスク管理のスキルは、近年急速に需要が拡大している複数の職種で直接活かすことができます。特に注目したい職種は以下のとおりです。
AIリスク管理スキルが活きる注目職種
・プロンプトエンジニア:AIへの指示設計を専門とし、ハルシネーション抑制の知識が中核スキルとなる。求人ボックスの2025年データによると平均年収は約818万円
・AIコンサルタント:企業のAI導入を支援し、リスク評価やツール選定をリードする
・AIガバナンス担当:組織のAI利用ルール策定・運用を担い、特に金融・医療など規制産業で需要が高い
・AIリスク&セキュリティコンサルタント:AIの安全な導入を専門的に支援する新興ポジション
転職先としては、AI開発企業やITコンサルティングファームのほか、自社でAI活用を推進する大手企業のDX推進部門なども有力な選択肢です。
ハルシネーション対策を学べるおすすめの方法
ハルシネーション対策のスキルを体系的に身につけるには、いくつかの学習アプローチがあります。目的やレベルに応じて選びましょう。
おすすめの3つの学習アプローチ
・実践学習:ChatGPTやClaudeの無料プランを使い、さまざまなプロンプトを試して出力の変化を比較する。ハルシネーションが起きやすいパターンと抑制方法を体感的に学べる
・オンライン講座:GoogleやMicrosoftの無料AIリテラシー講座、Courseraの生成AI関連コースなどで体系的に知識を習得する。RAGやプロンプトエンジニアリングに特化したコースもある
・資格取得:Google Cloud認定資格やAWS認定のAI関連資格、日本ディープラーニング協会の「G検定」などを目指す。AIリテラシーの基礎を体系的に証明でき、転職市場でも評価される
まずは実践学習から始め、興味が深まったらオンライン講座や資格取得にステップアップしていくのが効率的です。
まとめ:ハルシネーションを正しく理解して生成AIを安全に活用しよう
ハルシネーションとは、生成AIが事実と異なる情報をもっともらしく出力してしまう現象であり、学習データの不足や偏り、プロンプトの曖昧さ、LLMの確率的な文章生成という仕組み上の限界が主な原因です。弁護士が架空の判例を裁判所に提出した事例やGoogle Bardのデモでの誤情報など、実際にビジネスや社会に深刻な影響を及ぼしたケースも報告されています。対策としては、プロンプトの明確化、ファクトチェックの徹底、RAGの活用、社内ガイドラインの整備、複数AIでのクロスチェックの5つを組み合わせることが効果的です。ハルシネーションのリスクを正しく理解し対処できるスキルは、AI時代のキャリアにおいても大きな強みとなります。生成AIを「便利だが間違える可能性がある道具」と認識したうえで、検証を怠らず安全に活用していきましょう。